 Image credit: Unsplash
Image credit: Unsplash
Abstract
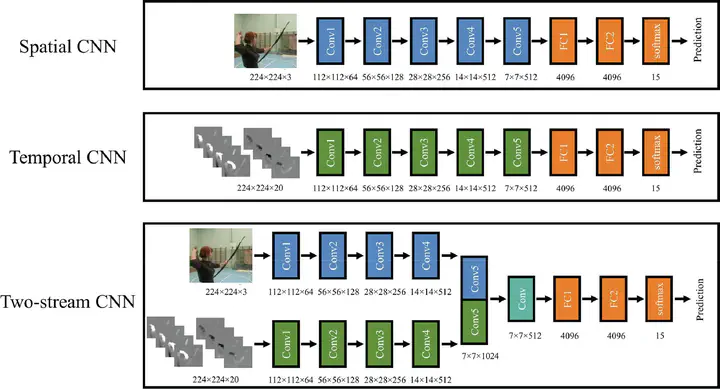
Visual recognition of biological motion recruits form and motion processes supported by both dorsal and ventral pathways. This neural architecture inspired the two-stream convolutional neural network (CNN) model, which includes a spatial CNN to process appearance information in a sequence of image frames, a temporal CNN to process optical flow information, and a fusion network to integrate the features extracted by the two CNNs and make final decisions about action recognition. In five simulations, we compared the CNN model’s performance with classical findings in biological motion perception. The CNNs trained with raw RGB action videos showed weak performance in recognizing point-light actions. Additional transfer training with actions shown in other display formats (e.g., skeletal) was necessary for CNNs to recognize point-light actions. The CNN models exhibited largely viewpoint-dependent recognition of actions, with a limited ability to generalize to viewpoints close to the training views. The CNNs predicted the inversion effect in the presence of global body configuration, but failed to predict the inversion effect driven solely by local motion signals. The CNNs provided a qualitative account of some behavioral results observed in human biological motion perception for fine discrimination tasks with noisy inputs, such as point-light actions with disrupted local motion signals, and walking actions with temporally misaligned motion cues. However, these successes are limited by the CNNs’ lack of adaptive integration for form and motion processes, and failure to incorporate specialized mechanisms (e.g., a life detector) as well as top-down influences on biological motion perception.
Yujia Peng
Assistant Professor of Psychology
Yujia Peng is an assistant professor at the School of Psychological and Cognitive Sciences, Peking University.